[데이터 시각화] 6. ggplot2
by Rev_막대그래프
geom_bar()
install.packages("ggplot2") # 처음에 한 번만 설치
library(ggplot2) # libarary() 함수를 사용해서 불러오기만 하면 됨
data(diamonds) # ggplot2 패키지 안에 내장되어 있는 데이터. data() 함수 사용
> str(diamonds)
tibble [53,940 x 10] (S3: tbl_df/tbl/data.frame)
$ carat : num [1:53940] 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num [1:53940] 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num [1:53940] 55 61 65 58 58 57 57 55 61 61 ...
$ price : int [1:53940] 326 326 327 334 335 336 336 337 337 338 ...
$ x : num [1:53940] 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num [1:53940] 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num [1:53940] 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...ggplot2 실습을 위하여 53,940 X 10의 diamonds 데이터를 불러왔다.
ggplot(data = diamonds) + geom_bar(aes(x = cut))
data = diamonds : 그래프를 그리는데 사용하는 데이터는 diamonds를 사용한다.
그리고 그래프에서 추가적으로 작성할 내용이 있으면 뒤에 +를 붙여 사용해준다.
geom_bar()는 막대그래프를 사용한다는 의미이다.
aes()는 변수에 대한 정보를 할당한다는 의미이며, x = cut으로 설정하여 X-축에 cut 이라는 변수를 할당한다.
이는 1차원 그래프이며, 그래프를 그리는데 하나의 변수가 투입되었다.
변수의 개수가 1개 라는 것은 그래프의 차원이 1차원이라는 의미이며,
그래프를 그릴 때 투입된 변수의 개수는 그래프의 차원(2차원, 3차원 등) 수와 동일한 의미를 가진다.
그래프의 차원이 높을수록(투입된 변수가 많을수록) 고차원 그래프가 된다. 정보 UP
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = cut))
여기서에는 추가로 fill = cut을 추가해주었는데, 이는 색을 cut을 기준으로 채워넣으라는 의미이다.
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = clarity))
X-축은 cut 변수를 할당하고, 막대기 색은 clarity로 변수를 할당했다.
시각화에 투입된 변수는 2개(cut, clarity)이기 때문에 2차원 그래프이다.
ggplot(data=diamonds) + geom_bar(aes(x = cut, fill = clarity),
position ="stack") + ggtitle('Position = "stack"')
앞서 만들었던 그래프에 position = "stack"을 사용하여 변수 cut 값에서 clarity를 수직으로 막대를 나열한다. (위로 쌓아올리는 형태) 이는 default 값이기 때문에 써주지 않아도 기본값으로 위와 같은 데이터가 나온다.
그리고 ggtitle()은 그래프의 제목을 표시한다.
ggplot(data=diamonds) + geom_bar(aes(x = cut, fill=clarity),
position ="dodge") + ggtitle('Position = "dodge"')
position = "dodge"는 변수 cut 값에서 clarity 값을 수평으로 막대를 나열한다.
원 그래프
geom_bar + coord_polar()
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = cut), width = 1) +
coord_polar()
width는 파이의 너비를 의미한다. 여기서는 width = 1로 설정해주었다.
coord_polar()는 막대 그래프를 파이 형태로 그려준다.
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = cut), width = 0.3) +
coord_polar()
여기서는 width = 0.3 으로 설정해주었다. 보아하니 width를 1로 설정해주는게 더 나은듯 하다.
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = cut), width = 1) +
coord_polar() + facet_wrap( ~ clarity)
facet_wrap( ~ clarity)를 추가해주었는데, 범주형 변수인 clarity의 범주별로 따로따로 구분해서 폴리 차트를 그렸다.
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = cut), width = 1) +
coord_polar() + facet_grid(color ~ clarity)
위의 폴리 차트는 두 개의 범주형 변수에 대해서 범주들을 따로 구분해서 그렸다.
facet_grid(color ~ clarity)는 ~의 왼쪽 변수(color)는 y축으로, ~의 오른쪽 변수(clarity)는 x축에 범주별로 구분해서 그래프를 그린다.
상자 그림
geom_boxplot()
data(mtcars)
> str(mtcars)
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...상자 그림 실습을 위하여 mtcar 데이터를 불러왔다. 32 X 11 데이터이다.
여기서 cyl은 실제로는 범주형 변수이나 데이터에서는 num으로 입력되어 있음
ggplot(data=mtcars, aes(x=factor(cyl), y=mpg, fill = factor(vs))) + geom_boxplot()
factor()은 해당 변수를 범주형 변수로 변환하는 것이다.
변수 vs와 변수 cyl별로 변수 mpg를 비교하기 위하여 상자 그림을 그린 것이다.
변수 cyl가 4일때가 mpg가 가장 높으며, 그 다음으로 6일때이고, cyl이 8일때 mpg가 가장 낮음
ggplot(data=mtcars, aes(x=factor(cyl), y=mpg, fill = factor(vs))) +
geom_boxplot() + geom_jitter(width = 0.1)
geom_jitter()는 데이터를 약간의 편차를 두고 점으로 뿌리는 형태를 표현한다.
width = 0.1로 점들의 간격을 0.1로 설정했다.
변수 vs별로 분석해보면, cyl=4 일때는 vs=1인 경우만 존재하며, cyl=6일때는 vs=0일때가 더 mpg가 높고, cyl=8일 때는 vs=0인 경우만 존재한다.
> data(mpg)
> str(mpg)
tibble [234 x 11] (S3: tbl_df/tbl/data.frame)
$ manufacturer: chr [1:234] "audi" "audi" "audi" "audi" ...
$ model : chr [1:234] "a4" "a4" "a4" "a4" ...
$ displ : num [1:234] 1.8 1.8 2 2 2.8 2.8 3.1 1.8 1.8 2 ...
$ year : int [1:234] 1999 1999 2008 2008 1999 1999 2008 1999 1999 2008 ...
$ cyl : int [1:234] 4 4 4 4 6 6 6 4 4 4 ...
$ trans : chr [1:234] "auto(l5)" "manual(m5)" "manual(m6)" "auto(av)" ...
$ drv : chr [1:234] "f" "f" "f" "f" ...
$ cty : int [1:234] 18 21 20 21 16 18 18 18 16 20 ...
$ hwy : int [1:234] 29 29 31 30 26 26 27 26 25 28 ...
$ fl : chr [1:234] "p" "p" "p" "p" ...
$ class : chr [1:234] "compact" "compact" "compact" "compact" ...이번에는 mpg데이터를 불러와서 box plot 실습을 해보고자 한다.
p <- ggplot (data=mpg, aes(x=class, y=hwy))
p + geom_boxplot()
p + geom_boxplot() + geom_jitter(width = 0.2)
class별로 hwy값을 알아보았다.
p + geom_boxplot(fill = "white", colour = "blue")
상자의 색깔을 상자 안에는 white로, 테두리는 blue로 나타내었다.
p + geom_boxplot(outlier.colour = "red", outlier.shape = 3)
outlier는 전체 데이터 범위에서 극단적으로 벗어나는 데이터를 의미한다.
outlier.colour로 이상치의 점 색깔을 지정하고, outlier.shape으로 이상치 점의 모양을 결정한다.
ggplot(data=diamonds, aes(x=carat, y=price)) +
geom_boxplot(aes(group = cut_width(carat, 0.25)), outlier.alpha = 0.1)
diamonds 데이터로도 상자 그림을 그려보았다.
cut_width(carat, 0.25)는 변수 carat을 0.25 간격으로 계급구간을 나눈다는 의미이다.
outlier.alpha는 이상치의 색깔 진하기 정도를 의미하며, 이 데이터는 0과 1사이의 값을 가지며 1에 가까울수록 진해진다.
히스토그램
geom_histogram()
ggplot(data=diamonds, aes(x=carat)) +
geom_histogram(binwidth=0.3, fill = "blue", colour = "white")
히스토그램은 계급구간의 변화에 따라서 히스토그램의 형태가 달라진다.

각각 binwidth를 0.7, 1.5, 0.2로 설정했을 때의 히스토그램이다. 그래프의 정보량의 차이가 명확히 있다.
계급구간 너비가 극단적으로 작으면 히스토그램의 정보량은 많아지지만, 너무 복잡해서 해석하기가 힘들다. 따라서 적절한 계급구간 너비를 선택해야 할 것이다.
p2 <- p1 + facet_grid(~ cut)
facet_grid(~ cut)는 범주별로 히스토그램을 가로로 나열한다.
p3 <- p1 + facet_grid(cut~.)
facet_grid(cut~.)는 범주별로 히스토그램을 세로로 나열한다.
두 개의 히스토그램은 동일한 정보를 갖고 있지만 결과를 해석하는 면에서는 차이가 있다.
어느 히스토그램이 효과적으로 해석할 수 있을까?
p4 <- p1 + facet_grid(cut ~ color)
범주형 변수 cut별로 범주형변수 color별로 carat에 대한 히스토그램을 시각화하였다.
두 개의 범주형 변수에 대한 각 범주별 carat에 대한 히스토그램이다.
ggplot(data = diamonds, aes(x=carat, colour=color)) + geom_histogram()
colour = color로 변수 color를 색깔로 구분해서 carat에 대한 히스토그램을 그렸다.
ggplot(data = diamonds, aes(x=carat, colour=color)) + geom_histogram(binwidth=0.1)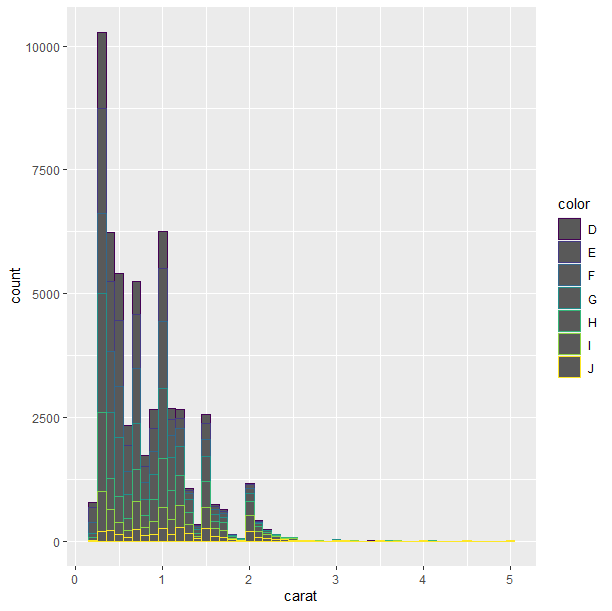
binwidth = 0.1로 설정하여 히스토그램의 너비를 설정했다.
ggplot(aes(x=carat, fill=cut), data=diamonds) + geom_histogram(alpha=0.6, binwidth=0.1)
fill = cut으로 cut별로 색깔을 입히고, alpha = 0.6를 통하여 색의 진하기를 0.6으로 설정하였다.
산점도
geom_point()
이전에 사용했던 diamonds 데이터로 산점도를 실습해보자.
산점도는 두 개의 연속형 변수에 대한 선형관계를 분석할 때 사용한다.
일반적으로 Y축 변수는 알고자하는 변수이고, X축 변수는 Y축 변수에 영향을 미치는 변수이다.
ggplot(data=diamonds, aes(x=carat, y=price)) + geom_point()
geom_point()로 데이터의 산점도를 표현한다.
다이아몬드는 가격(price) 변수에 더 관심이 있다. 무게(carat)는 가격에 영향을 미치는 변수
그래서 가격을 Y축, 무게를 X축으로 설정했다.
결과를 분석해보면, 무게가 증가할 수록 가격은 올라가는 경향이 있다.
무게가 증가할수록 가격은 기하급수적으로 증가하는 패턴이다.
가격이 증가할수록 무게의 편차는 커지는 경향이 있다.
ggplot(data=diamonds, aes(x=carat, y=price)) + geom_point(aes(colour=clarity)) +
geom_smooth()
geom_point(aes(colour=clarity))를 통하여 clarity별로 색깔을 구분해서 산점도를 표시하였다.
무게가 증가할수록 가장 빠른 속도로 증가하는 다이아몬드는 무엇일까?
-> clarity가 IF인 경우
무게가 증가할수록 가장 느린 속도로 가격이 증가하는 다이아몬드는 무엇일까?
-> clarity가 I1인 경우
geom_smooth()을 추가하여 전체적인 데이터 패턴을 표시하기 위해서 곡선 추세선을 추가했다.
추세곡선은 전체적인 데이터의 경향성을 곡선형태로 표현한다.
추세곡선 주위에 있는 음영은 신뢰구간을 의미하며, 신뢰구간의 폭이 좁을수록 예측의 정확도가 높다.
p1 <- ggplot(data=diamonds, aes(x=carat, y=price)) + geom_point(aes(colour=clarity)) +
geom_smooth(method="lm")
p1
색깔을 구분하는 colour=는 geom_point() 함수 안에 있음을 생각하자.
geom_smooth(method="lm")는 추세선이 곡선이 아닌 직선으로 표시하라는 의미이다.
데이터 전체의 경향성을 나타내는 추세선이 곡선이 직관적일까 직선이 직관적일까?
곡선일 때는 해석이 좀 더 복잡하지만 정보량은 많고, 직선일 때는 해석이 좀 더 단순하지만 정보량이 부족하다.
이 그래프의 단점은 위쪽 여백이 너무 많다는 점이다. Y축 변수를 20000 이하로 조정할 필요가 있다.
p2 <- p1 + scale_y_continuous(limits = c(0, 20000)) + scale_x_continuous(limits = c(0, 5))
p2
scale_y_continuous()와 scale_x_continuous() 변수는 X축과 Y축의 범위를 설정한다.
y는 0에서 20000까지, x는 0에서 5까지로 설정했다.
ggplot(data=diamonds, aes(x=carat, y=price, colour=clarity)) + geom_point() +
geom_smooth()
colour = clarity가 ggplot() 함수 안에 있으면 geom_point()나 geom_smooth()는 clarity별로 구분해서 추세곡선을 추가한다.
ggplot(data=diamonds, aes(x=carat, y=price, colour=clarity)) + geom_point() +
geom_smooth(method="lm")+ scale_y_continuous(limits = c(0, 20000))+
scale_x_continuous(limits = c(0, 6))
추세선을 clarity별로 직선으로 표현했다.
ggplot(diamonds, aes(x=carat, y=price, colour=table)) + geom_point() +
scale_colour_gradient()
colour = table로 연속형 변수인 table의 값에 따라 색깔을 구분한다.
scale_colour_gradient()는 색깔을 table의 값에 따라 점진적으로 변해가도록 한다.
ggplot(diamonds, aes(x=carat, y=price, colour=carat)) + geom_point() +
scale_colour_gradient(low='white', high='red')
scale_colour_gradient()에 색을 지정하는 옵션을 추가하였다.
색깔을 지정하는 carat의 값이 작을수록 흰색, 클수록 푸른색이 되도록 지정했다.
scale_colour_gradient(low='#05D9F6', high='#5011D1')와 같은 형식으로도 가능
ggplot(diamonds, aes(x=carat, y=price, colour=color)) + geom_point() +
scale_colour_hue(l = 40, c = 30)

scale_colour_hue() 함수를 사용하여 점의 색깔을 선명도(l)와 채도(c)로 표시한다.
ggplot(data = diamonds) + geom_point(mapping = aes(x = carat, y = price), colour="blue") +
geom_density2d(mapping = aes(x = carat, y = price), colour="yellow")
geom_density2d() 함수를 사용하여 2차원 밀도 그래프를 산점도에 추가하였다.
data(economics)
> str(economics)
spec_tbl_df [574 x 6] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ date : Date[1:574], format: "1967-07-01" "1967-08-01" ...
$ pce : num [1:574] 507 510 516 512 517 ...
$ pop : num [1:574] 198712 198911 199113 199311 199498 ...
$ psavert : num [1:574] 12.6 12.6 11.9 12.9 12.8 11.8 11.7 12.3 11.7 12.3 ...
$ uempmed : num [1:574] 4.5 4.7 4.6 4.9 4.7 4.8 5.1 4.5 4.1 4.6 ...
$ unemploy: num [1:574] 2944 2945 2958 3143 3066 ...이번에는 ecnomice 데이터를 사용해보자. 574 X 6 데이터이다.
ggplot(data = economics) + geom_point(aes(x = date, y = unemploy))
연도가 지남에 따라서 실업자 수가 어떤 추이로 변화하는지 나타내는 산점도 결과이다.
1980년 초반까지는 실업자 수가 등락을 반복하지만 전체적으로는 증가하는 추세를 보이고 있다.
그러나 그 이후 2000년대 후반까지는 등락을 반복하다가, 2000년대 후반 이후로는 급격하게 증가한 후, 그 이후로는 급격하게 감소하였다.
ggplot(data = economics) + geom_line(aes(x = date, y = unemploy))
ggplot(data = economics[1:150, ]) + geom_step(aes(x = date, y = unemploy))
economics[1:150, ]의 의미는 데이터는 행렬구조로 되어 있는데, 행렬구조로 표현할 때 []을 사용한다.
data[행(케이스), 열(변수)] : economics 데이터의 행(케이스)는 첫 번째부터 150번째만 사용한다. 열(변수)는 공백으로 표현되어 있는데, 모든 것을 사용하는 것을 의미한다.
시간의 변화에 따라서 변화 추세를 분석할 때는 산점도보단 꺾은선 그래프가 효율적이라고 할 수 있다.
'복수전공' 카테고리의 다른 글
| [현대사회의 데이터와 통계학] 5. Matplotlib로 그래프 그리기 (0) | 2021.11.10 |
|---|---|
| [범주형 데이터분석] 4. 군집화(Clustering) (0) | 2021.11.05 |
| [현대사회의 데이터와 통계학] 4. Pandas : 구조적 데이터 생성하기 (0) | 2021.11.03 |
| [실험계획법] 중간고사 대비 (0) | 2021.11.01 |
| [실험계획법] 3. 일원배치법 (0) | 2021.11.01 |
블로그의 정보
Hi Rev
Rev_