[데이터 시각화] 4. 비교 시각화
by Rev_히트맵
연속형 변수를 대상으로 시각화한다.
> bball <- read.csv("http://datasets.flowingdata.com/ppg2008.csv", header=TRUE)
> str(bball) # 데이터에 대한 구조
'data.frame': 50 obs. of 21 variables:
$ Name: chr "Dwyane Wade " "LeBron James " "Kobe Bryant " "Dirk Nowitzki " ...
$ G : int 79 81 82 81 67 74 51 50 78 66 ...
$ MIN : num 38.6 37.7 36.2 37.7 36.2 39 38.2 36.6 38.5 34.5 ...
$ PTS : num 30.2 28.4 26.8 25.9 25.8 25.3 24.6 23.1 22.8 22.8 ...
$ FGM : num 10.8 9.7 9.8 9.6 8.5 8.9 6.7 9.7 8.1 8.1 ...
$ FGA : num 22 19.9 20.9 20 19.1 18.8 15.9 19.5 16.1 18.3 ...
$ FGP : num 0.491 0.489 0.467 0.479 0.447 0.476 0.42 0.497 0.503 0.443 ...
$ FTM : num 7.5 7.3 5.9 6 6 6.1 9 3.7 5.8 5.6 ...
$ FTA : num 9.8 9.4 6.9 6.7 6.9 7.1 10.3 5 6.7 7.1 ...
$ FTP : num 0.765 0.78 0.856 0.89 0.878 0.863 0.867 0.738 0.868 0.793 ...
$ X3PM: num 1.1 1.6 1.4 0.8 2.7 1.3 2.3 0 0.8 1 ...
$ X3PA: num 3.5 4.7 4.1 2.1 6.7 3.1 5.4 0.1 2.3 2.6 ...
$ X3PP: num 0.317 0.344 0.351 0.359 0.404 0.422 0.415 0 0.364 0.371 ...
$ ORB : num 1.1 1.3 1.1 1.1 0.7 1 0.6 3.4 0.9 1.6 ...
$ DRB : num 3.9 6.3 4.1 7.3 4.4 5.5 3 7.5 4.7 5.2 ...
$ TRB : num 5 7.6 5.2 8.4 5.1 6.5 3.6 11 5.5 6.8 ...
$ AST : num 7.5 7.2 4.9 2.4 2.7 2.8 2.7 1.6 11 3.4 ...
$ STL : num 2.2 1.7 1.5 0.8 1 1.3 1.2 0.8 2.8 1.1 ...
$ BLK : num 1.3 1.1 0.5 0.8 1.4 0.7 0.2 1.7 0.1 0.4 ...
$ TO : num 3.4 3 2.6 1.9 2.5 3 2.9 1.8 3 3 ...
$ PF : num 2.3 1.7 2.3 2.2 3.1 1.8 2.3 2.8 2.7 3 ...외부 사이트에 있는 데이터를 불러왔다.
이 bball 데이터는 행이 50명의 선수이고, 열은 21개로 구성되어 있다.
edit(bball)
edit() 함수를 사용하면 위와 같은 창이 뜨며, 이를 통해 데이터를 편집할 수 있다.
이런 형태의 데이터는 통계분석에 가장 많이 사용되고 있는 데이터 구조이며, 이를 데이터 프레임 형태의 데이터라고 한다.
일단 이번에 사용할 데이터 정보를 알아보았고, 히트맵 시각화를 진행할 예정이다. 히트맵 시각화는 다음과 같은 순서로 진행된다.
- 행 이름 지정
- 연속형 변수 중 분석하고 싶은 변수 선택
- 행렬 구조로 변환
- 히트맵 함수를 사용한 시각화
# STEP 1 : 행 이름 지정(데이터를 특정지을 수 있는 변수를 행이름으로 지정)
row.names(bball) <- bball$Name먼저 행 이름을 지정한다. 선수별 데이터를 나타낼 것이기 때문에 행 이름을 Name 변수로 지정하였다.
# STEP 2 : 분석하고자 하는 변수 선택(반드시 연속형 변수)
bball <- bball[,2:20] # 연속형 변수 선택bball 데이터에서 2번째 변수부터 20번째 변수까지 선택한다.
# STEP 3 : 행렬구조로 변환
bball_matrix <- data.matrix(bball)히트맵 함수를 사용하기 위해서는 반드시 데이터의 형태가 행렬구조가 되어야 한다.
data.matrix()는 행렬 구조로 변환시키는 함수이다.
# STEP 4 : 히트맵 함수를 사용한 시각화
bball_heatmap <- heatmap(bball_matrix, Rowv=NA, Colv=NA, col=cm.colors(256),
scale="column", margins=c(5,10))
bball_heatmap <- heatmap(bball_matrix, col=cm.colors(256),
scale="column", margins=c(5,10))이제 heatmap() 함수를 사용하여 시각화를 두 가지 경우로 해보았다.

Rowv = NA, Colv = NA 옵션의 유무이다. 이 옵션을 주면 덴드로그램이 없는 히트맵이 출력되고, 이게 없다면 덴드로그램이 있는 히트맵이 출력된다. 오른쪽은 단순 히트맵보다 정보량이 더 많다고 할 수 있다.
install.packages("RColorBrewer") # 색상 전문 패키지
library(RColorBrewer)
bball_heatmap <- heatmap(bball_matrix, Rowv=NA, Colv=NA, col=brewer.pal(9, "Blues"),
scale="column", margins=c(5,10)) # blue 톤으로 9단계로 나누어 구분
bball_heatmap <- heatmap(bball_matrix, Rowv=NA, Colv=NA, col=brewer.pal(9, "Greens"),
scale="column", margins=c(5,10))
bball_heatmap <- heatmap(bball_matrix, Rowv=NA, Colv=NA, col=brewer.pal(9, "Reds"),
scale="column", margins=c(5,10))색을 바꾸고 싶다면 RColorBrewer 패키지를 이용할 수 있다.

스타 차트
install.packages("aplpack")
library(aplpack)
crime <- read.csv("C:/BNG/crime.csv", header=TRUE)
> str(crime)
'data.frame': 50 obs. of 12 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ state : chr "alabama" "alaska" "arizona" "arkansas" ...
$ murder : num 8.2 4.8 7.5 6.7 6.9 3.7 2.9 4.4 5 6.2 ...
$ Forcible_rate : num 34.3 81.1 33.8 42.9 26 43.4 20 44.7 37.1 23.6 ...
$ Robbery : num 141.4 80.9 144.4 91.1 176.1 ...
$ aggravated_assult : num 248 465 327 387 317 ...
$ burglary : num 954 622 948 1085 693 ...
$ larceny_theft : num 2650 2599 2965 2711 1916 ...
$ motor_vehicle_theft: num 288 391 924 262 713 ...
$ population : int 4627851 686293 6500180 2855390 36756666 4861515 3501252 873092 18328340 9685744 ...
$ Latitude : num 32.8 61.4 33.7 35 36.1 ...
$ Longitude : num -86.8 -152.4 -111.4 -92.4 -119.7 ...50 X 12 로 구성된 crime 데이터를 준비하였다. 각 주별 범죄 데이터이다.
이번에는 스타 차트 시각화를 할 것이다.
히트맵 시각화와 마찬가지로 아래와 같은 순서로 진행된다.
- 행 이름 지정
- 연속형 변수 중 분석하고 싶은 변수 선택
- 스타 차트 시각화
# STEP 1 : 행이름 지정
row.names(crime) <- crime$state데이터를 구분해주는 변수는 주 이름을 나타내는 state이다.
# STEP 2 : 분석할 변수 선택(연속형 변수)
crime <- crime[, 2:7]연속형 변수 중에서 2번째 변수부터 7번째 변수까지를 선택하였다.
# STEP 3 : 스타 차트 시각화
stars(crime, flip.labels=FALSE, key.loc=c(15, 1.5), full=TRUE, draw.segments=FALSE)
stars(crime, flip.labels=FALSE, key.loc=c(15, 1.5), full=FALSE, draw.segments=FALSE)
stars(crime, flip.labels=FALSE, key.loc=c(15, 1.5), full=TRUE, draw.segments=TRUE)
stars(crime, flip.labels=FALSE, key.loc=c(15, 1.5), full=FALSE, draw.segments=TRUE)

데이터 빈도를 180도로 볼려면 full=FALSE, 360도로 보려면 full=TRUE로 설정했다.
그리고 흑백으로 보려면 draw.segments=FALSE, 컬러로 보려면 draw.segments=TRUE 옵션을 설정했다.
시각화 결과로 가장 좋은 그래프는 어떤 것일까?
180도 보다는 360도가 더 전달력이 좋고, 흑백보다는 컬러 차트가 더 전달력이 좋다고 할 수 있다.
비교 분류 시각화
비교 분류 시각화는 덴드로그램을 이용한 분류와 히트맵을 이용한 비교를 의미한다.
> USArrests <- read.csv("C:/BNG/USArrests.csv", header=TRUE)
> str(USArrests)
'data.frame': 50 obs. of 5 variables:
$ X : chr "Alabama" "Alaska" "Arizona" "Arkansas" ...
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...실습을 위하여 50 X 5의 USArrests 데이터를 가져왔다.
여기서 변수 X가 주(state)이름을 나타내기 때문에 X를 행 이름으로 지정해야 한다.
# STEP1 : 행이름 지정
row.names(USArrests) <- USArrests$X
# USArrests 데이터셋 속에 있는 변수 X를 행이름(row.names)으로 지정
# STEP2 : 분석대상 변수 선택(연속형 변수)
USArrests <- USArrests[, 2:5] # 2번째 변수부터 5번째 변수까지 선택2번째부터 5번째 변수를 분석대상으로 지정하였다.
참고로 2, 4, 5번째 변수만 선택하고 싶은 경우에는 [, 2:5] 말고 [, c(2, 4, 5)]와 같이 지정해주면 된다.
# STEP3 : 행렬구조 변환(data.matrix() 함수 사용)
USArrests_matrix <- data.matrix(USArrests) # 행렬구조로 변환# STEP4 : 히트맵 작성
rc <- rainbow(nrow(USArrests_matrix), start=0, end=.3) # 케이스(row)의 유사성 정도를 색깔로 구분
cc <- rainbow(ncol(USArrests_matrix), start=0, end=.3) # 변수(col)의 유사성 정도를 색깔로 구분
hv <- heatmap(USArrests_matrix, col = cm.colors(256), scale="column", RowSideColors = rc,
ColSideColors = cc, margin=c(5,10), xlab = "Type of crime", ylab= "States",
main = "Heatmap of USArrests data")cm.color(256)은 붉은색부터 푸른색까지 256 톤으로 변수값의 크기를 표현한다는 의미이다.
scale = "column"은 변수를 표준화 시켜 단위를 통일한다는 의미이다.
여기서도 덴드로그램을 없애려면 Rowv=NA, Colv=NA를 추가해주면 된다.

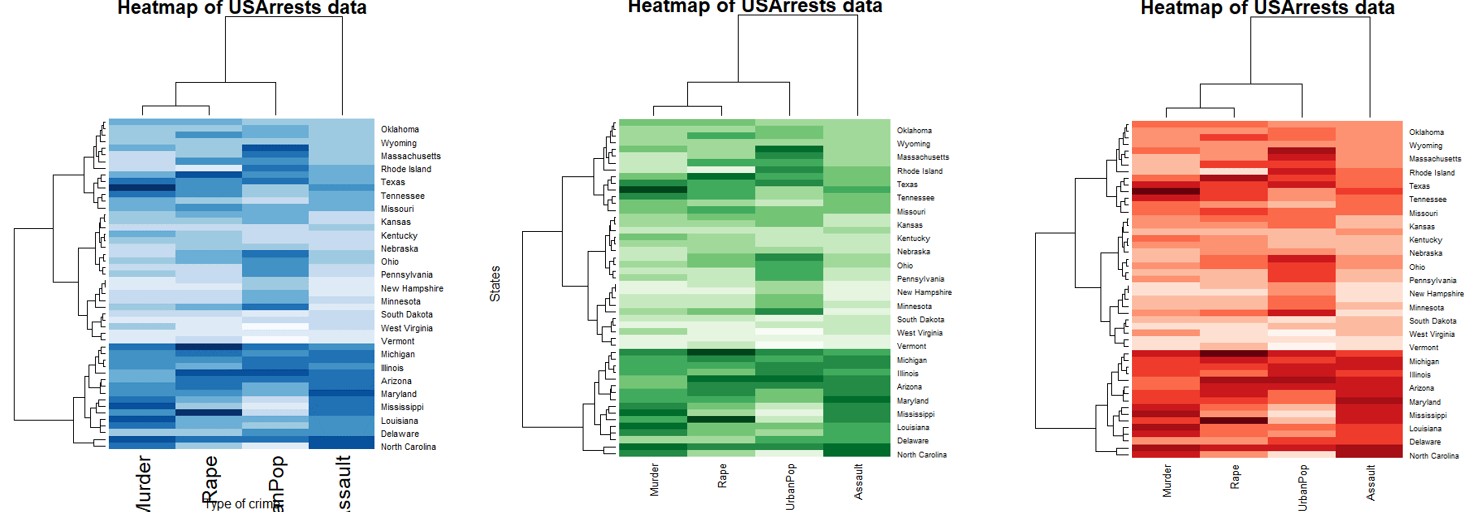
50개의 주별로 유사성이 있는 것을 분류하면 크게 3개의 집단으로 분류할 수 있다.
또한 4개의 변수를 유사성이 높은 순으로 분류해보면 Murder와 Rape가 가장 유사하면, 그 다음으로 UrbanPop, Assault의 순서로 유사한 것을 볼 수 있다.
하지만 케이스와 변수의 유사성에 따라 무지개 색으로 표현한 것은 그닥 이점이 있는 것 같진 않다.
hv <- heatmap(USArrests_matrix, col = cm.colors(256), scale="column", margin=c(5,10),
xlab = "Type of crime", ylab= "States", main = "Heatmap of USArrests data")무지개 색을 없애려면 RowSideColors = rc, ColSideColors = cc 항목을 제거해주면 된다.

library(RColorBrewer)
hv <- heatmap(USArrests_matrix, col=brewer.pal(9, "Blues"), scale="column", margin=c(5,10),
ylab= "States", main = "Heatmap of USArrests data")
# 글자 크기 설정
hv <- heatmap(USArrests_matrix, col=brewer.pal(9, "Greens"), scale="column", margin=c(5,10),
cexRow = 0.7, cexCol = 1, main = "Heatmap of USArrests data") # cexRow : 변수이름 글자 크기 조정
hv <- heatmap(USArrests_matrix, col=brewer.pal(9, "Reds"), scale="column", margin=c(5,10),
cexRow = 0.7, cexCol = 1, main = "Heatmap of USArrests data")RColorBrewer 패키지를 이용해 색도 바꿔줄 수 있고, 글자 크기를 조정하려면 cexRow, cexCol 옵션을 사용해 변수 이름의 글자 크기를 조정할 수 있다.
'복수전공' 카테고리의 다른 글
| [SAS 자료분석] 1. SAS파일 다루기 (0) | 2021.10.25 |
|---|---|
| [범주형 데이터분석] 2. 선형대수학(Linear Algebra) (0) | 2021.10.25 |
| [데이터 시각화] 3. 시간 시각화 (0) | 2021.10.24 |
| [데이터 시각화] 2. 분포 시각화 (0) | 2021.10.23 |
| [데이터 시각화] 1. 데이터 입출력 (0) | 2021.10.23 |
블로그의 정보
Hi Rev
Rev_